Background
This project, conducted as my Final Year Project at NTU, re-engineers the vLLM worker-controller architecture. My goal was to reduce cold start latency in large language model inference. You can view the repository here
Overview
vLLM is widely recognized for its state-of-the-art serving throughput, largely due to its efficient management of attention memory via PagedAttention. For developers and researchers, the PagedAttention paper offers a fascinating look into how OS-level memory concepts can be applied to Deep Learning.
Despite these optimizations, the standard vLLM architecture incurs high "cold-start" latency. This latency is negligible for static deployments but becomes a major hindrance in dynamic serving scenarios.
Current Implementation
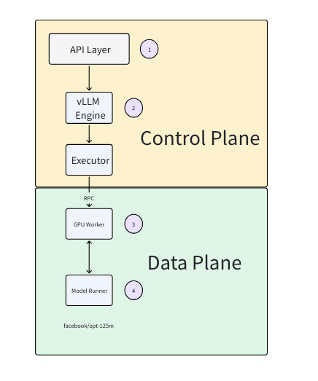
When a user serves a model, vllm serve facebook/opt-125m
-
A vLLM Config is first created using the arguments like model name. Other arguments include, tensor parallelism and pipeline parallelism, which is the number of GPUs.
-
The vLLM engine is then created using the configured vLLM config, which creates the executor.
-
The executor creates the GPU worker processes and communicates via RPC. In each GPU worker processes, python environment is set up and CUDA is initialized.
-
The model runner is created and the model is loaded onto the model runner. The API server is now ready for inference.
Addressing Inefficiency in Current vLLM architecture
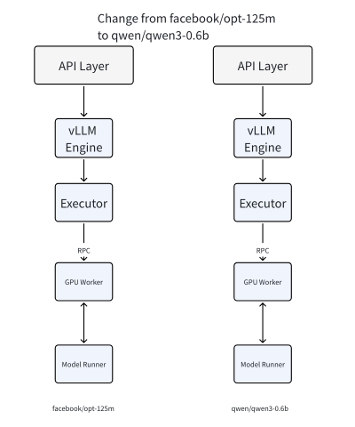
If the user wants to change a model, worker processes have to be created, as the current procedure creates the worker processes with the configured vLLM config. Hence, if we want to change models often, there will be a lot of worker process startup overhead.
Objective
The goal of this Worker Controller implementation is to decouple the GPU worker processes from the specific model configuration. The current vLLM architecture couples the worker process lifecycle with the model configuration. This means "cold starts" involve expensive Python initialization and CUDA context creation every time we switch models, leading to high latency for the end user. By keeping the worker processes (and their CUDA contexts) alive and "warm," we can swap models in and out significantly faster, enabling efficient serverless LLM inference.