Worker Controller vs Standard vLLM: Cold-Start Performance Analysis
Summary
This results presents a performance comparison between Worker Controller and Standard vLLM architectures, focusing on cold-start behavior. Our testing demonstrates that Worker Controller consistently reduces total cold-start time by approximately 2.24 seconds (17% speedup) in a representative run by optimizing the engine creation process and eliminating worker startup latency.
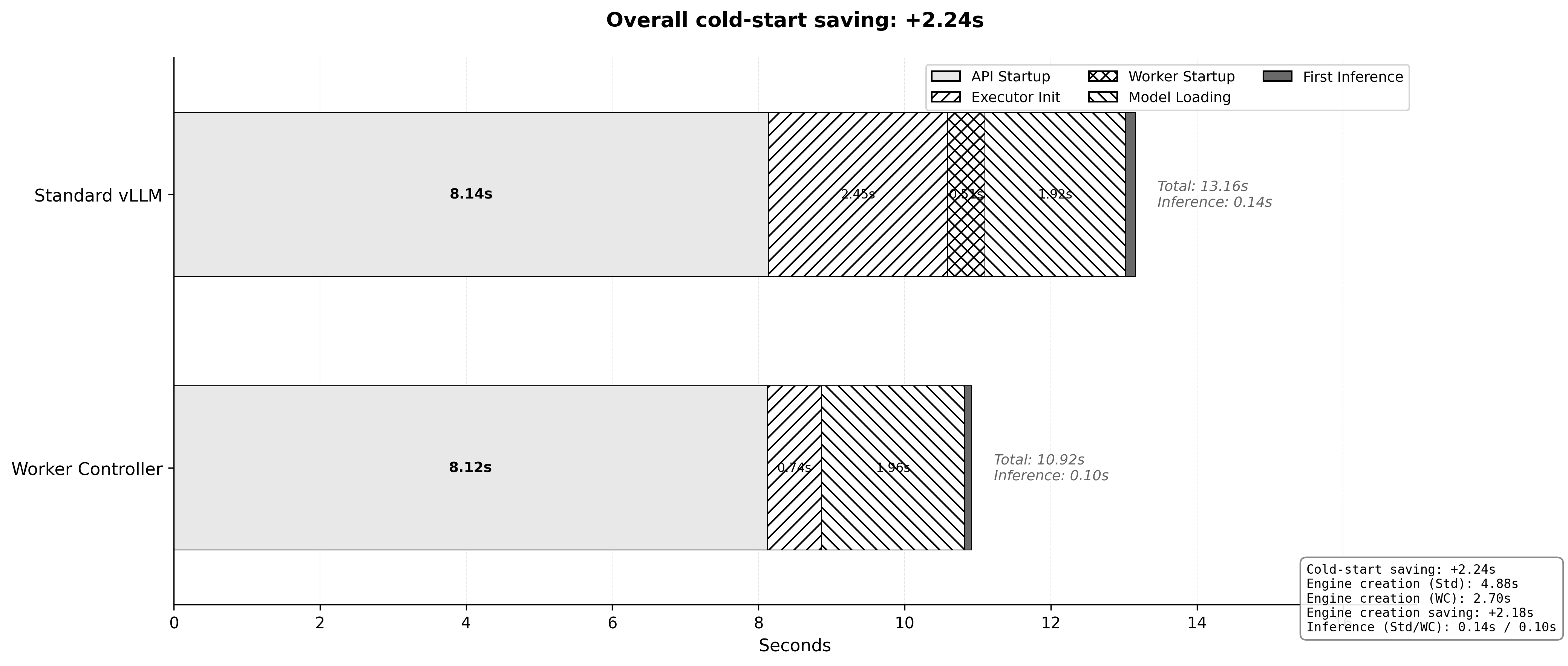
Key Finding: In a representative sequential run (Run 3), the Worker Controller reduced the total time to first token from 13.16s to 10.92s, driven entirely by a 45% reduction in the engine creation phase.
Performance Comparison
Test Configuration
- Model:
facebook/opt-125m - Methodology: 3 sequential cold-start runs comparing both architectures
- Representative Run: Run 3 (Data below)
Performance Breakdown (Representative Run - Run 3)
The following table breaks down the total time from request to first token, structured by the system's logical lifecycle:
| Stage | Component | Standard (s) | Worker Controller (s) | Delta (s) |
|---|---|---|---|---|
| 1. API Server Overhead | 8.14 | 8.12 | -0.02 | |
| 2. Engine Creation | 4.88 | 2.70 | -2.18 | |
| Executor Init & Config | 2.45 | 0.74 | -1.71 | |
| Worker Startup / Attach | 0.51 | 0.00 | -0.51 | |
| Model Loading | 1.92 | 1.96 | +0.04 | |
| 3. Inference | 0.14 | 0.10 | -0.04 | |
| TOTAL | 13.16 | 10.92 | -2.24 |
Key Performance Improvements
1. Engine Creation Phase
Total Stage Savings: 2.18s (45% Reduction)
The most significant performance gains occur during the Engine Creation phase (4.88s -> 2.70s). This improvement is driven by two key factors:
- Executor Init & Config (-1.71s): The core engine setup is optimized in the Worker Controller, likely due to reduced overhead in establishing distributed communication channels compared to the standard initialization.
- Worker Strategy (-0.51s): The cost of spawning new worker processes is completely eliminated by attaching to pre-warmed workers (0.00s), removing a fixed latency floor.
2. Consistent Model Loading
Comparable Performance (+0.04s)
Model loading times remained consistent between both architectures (1.92s vs 1.96s), indicating that the primary gains are strictly structural (process management and initialization) rather than I/O related.
3. API Server Overhead Stability
Consistent Baseline (~8.1s)
The "API Server Overhead" metric (~8.1s) represents the fixed cost of initializing the application framework (FastAPI, Uvicorn, Python imports) and is largely independent of the inference engine strategy. As shown in the data (8.14s vs 8.12s), this overhead is effectively identical, confirming that the comparison is fair and controlled.
Conclusions
When Worker Controller Provides Maximum Value
Worker Controller is most beneficial in scenarios involving:
- Multi-Model Serving: Repeatedly creating/deleting engines for different models.
- Sequential Loading Workflows: Loading models one after another.
- Dynamic Model Management: Frequent model swaps or updates.
- Development/Testing: Rapid iteration cycles requiring frequent restarts.
Performance Summary
-
Worker Controller consistently reduces total startup time, with savings of 2.24s in a representative run.
-
Engine Creation phase is accelerated by ~45%.
-
Worker startup latency is completely eliminated.
-
API Server Overhead remains constant, proving the optimization's specific efficacy.