Proposed Solution
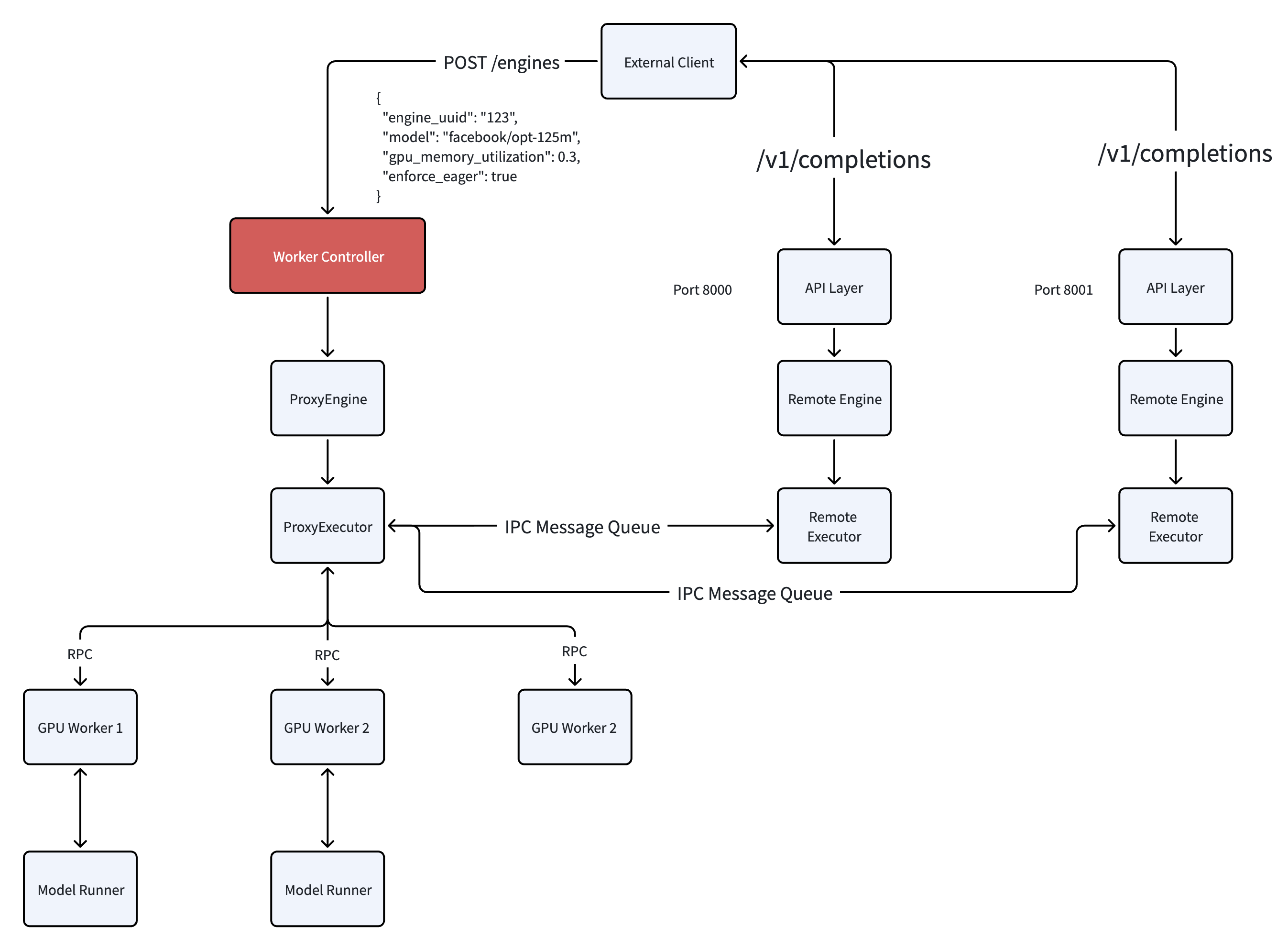
Worker Controller
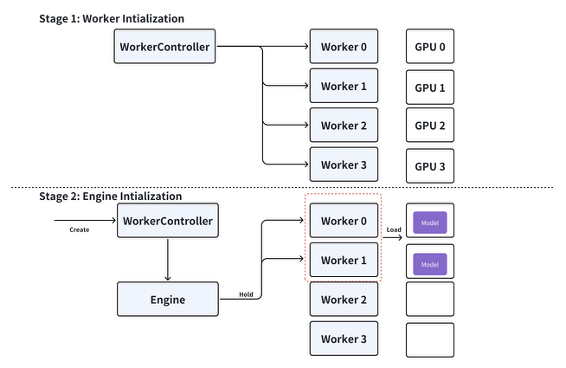
To overcome the cold-start latency inherent in the default vLLM architecture, we introduced a Worker Controller. This component fundamentally shifts the resource management paradigm from "process-per-model" to "process-as-a-resource."
Key Innovations
- Worker Pooling: Instead of spawning new processes for every model, we maintain a persistent pool of pre-initialized GPU workers (processes with CUDA context already established).
- Dynamic Binding: vLLM engines are modified to dynamically attach to these pre-warmed workers on demand, rather than creating them during initialization.
- Inter-Process Communication (IPC): A robust IPC mechanism allows the runtime API servers to command these pre-existing workers, facilitating efficient instruction and data transfer.
High Level Architecture
In this new architecture, the Worker Controller acts as the orchestrator:
- Initialization: At system startup, the Controller spawns a configurable number of "dummy" workers. These workers initialize their Python environments and CUDA contexts but do not load any model weights.
- Request Handling: When a request to serve a specific model (e.g.,
Llama-2-7b) arrives, the Controller identifies available workers from the pool. - Assignment: The selected workers are assigned to the new Engine instance.
- Model Loading: The workers load the specific model weights. Note that while weight loading is still necessary, the expensive process startup and CUDA initialization overhead is completely eliminated.